ISSN : 0975-2927
EISSN : 0975-9166

MALLAMMA V REDDY1*, HANUMANTHAPPA M.2*
1Department of Computer Science and Applications, Bangalore University, Bangalore-560 056, INDIA
2Department of Computer Science and Applications, Bangalore University, Bangalore-560 056, INDIA
* Corresponding Author : hanu6572@bub.ernet.in
Received : 06-11-2011 Accepted : 09-12-2011 Published : 12-12-2011
Volume : 3 Issue : 4 Pages : 340 - 345
Int J Mach Intell 3.4 (2011):340-345
DOI : http://dx.doi.org/10.9735/0975-2927.3.4.340-345
Conflict of Interest : None declared
Transliteration is mapping of pronunciation and articulation of words written in one script into another script. Transliteration should not be confused with translation, which involves a change in language while preserving meaning. CLIR is the acronym of a great variety of techniques, systems and technologies that associate information retrieval (normally from texts) in multilingual environments. Dictionaries have often been used for query translation in cross language information retrieval (CLIR). However, we are faced with the problem of translating Names and Technical Terms from English to Kannada/Telugu. The most important query words in information retrieval are often proper names. We present a method for automatically learning a transliteration model from a sample of name pairs in two languages.
Query translation, Bilingual Dictionaries, Transliteration.
India is a country with 22 official languages and use of computers is fast spreading not only to create employment in the IT sector but also to support productive use of IT in daily life - increase productivity and competitiveness, provide better quality of life, enable inclusiveness and strengthen democracy. Ability of different sections of people to use computers (and increasingly text and data over mobile phones) demand that the Basic Information Processing Kit for Indian languages is constantly upgraded for various hardware and software platforms, new tools added and work promoted with developers, ISVs and System Integrators and application developers to enable/support Indian languages use in different sectors/verticals. And increasingly, Indian language content in Digital form has to be created and supported for applications to be supported and reach a critical mass.
Cross-Language Information Retrieval (CLIR) is a special case of information retrieval in which retrieval is not restricted to the query language itself but extends to all languages supported by the system. CLIR [14] deals with the problem of issuing a query in one language and retrieving relevant information in other languages. It aims to help the user in finding relevant information without being limited by linguistic barriers. Proper names in general are very important in text. Since news stories especially revolve around people, places, or organizations, proper names play a major role in helping one distinguish between a general event (like a war) and a specific event.
Proper names in English are spelled in various ways. Despite the existence of one or more standard forms for someone’s name, it is common to find variations in transliterations of that name in different source texts, such as Goutham vs. Goutam. The problem is more pronounced when dealing with non-English names or when dealing with spellings by non-native speakers.
One possible method to generate transliteration is based on the use of dictionaries, which contains words in source language and their possible transliterated forms in target language. However, this is not a practical solution since proper nouns and technical terms, which are frequently transliterated, usually have rich productivity [1] . This paper discusses another approach based on machine learning to automate the process of machine transliteration.
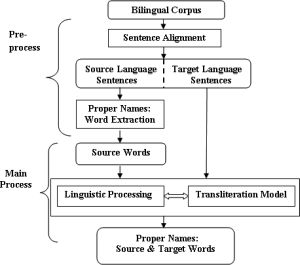
The Language transliteration is one of the important area in natural language processing. Machine Transliteration is the conversion of a character or word from one language to another without losing its phonological characteristics. It is an orthographical and phonetic converting process. Therefore, both grapheme and phoneme information should be considered. Accurate transliteration of named entities plays an important role in the performance of machine translation and cross-language information retrieval processes. The transliteration model must be design in such a way that the phonetic structure of words should be preserve as closely as possible. The overall machine transliteration system architecture as The proposed transliteration model can be applied to the tasks of the extraction of bilingual name and transliteration pairs. These tasks become more challenging for language pairs with different sound systems, we focus on the extraction of English-Kannada/Telugu name and transliteration pairs. However, the proposed framework is easily extendable to other language pairs.
For the purpose of extracting name and transliteration pairs from parallel corpora, a sentence alignment procedure is applied first to align parallel texts at the sentence level. Then, we use a part of speech tagger to identify proper nouns in the source text. After that, the machine transliteration model is applied to isolate the transliteration in the target text. In general, the proposed transliteration model can be further augmented by linguistic processing, which will be described in more detail in the next subsection. The overall process is summarized in [Fig-1] .
This is the first layer of the proposed model which gets an English word as input and simplifies the word by performing some pre-processing steps. At the first step, an English word goes through schwa deletion algorithm.
The transliteration system is trained from the lists of proper names in English and Kannada by using GIZA++ [11] , an extension of GIZA, which determines the translation probability. Training is done with the help of 3800 names in the both English and Kannada in tokenized form.
An input in target language that is Kannada language from last unit is forwarded to the post processing unit where some post processing tasks are applied to it. Post processing tasks further improve the results using various transliteration rules.
English is a West Germanic language that arose in the Anglo-Saxon kingdoms of England. It is one of six official languages of the United Nations. India is one of the countries where English is spoken as a second language. There are 21 consonant letters in English. These are B, C, D, F, G, H, J, K, L, M, N, P, Q, R, S, T, V, W, X, and Z. The rest of the letters of the alphabet are called vowels. The vowels are: A, E, I, O, U. As defined in the Constitution of India, English is one of the two official languages of communication (Hindi being the other) for India's federal government and is one of the 22 scheduled languages specified in the Eighth Schedule to the Constitution. A working knowledge of English has become a requirement in a number of fields, occupations and professions such as medicine and computing; as a consequence over a billion people speak English to at least a basic level [4] .
Kannada or Canarese is a language spoken in India predominantly in the state of Karnataka, Making it the 25th most spoken language in the world. It has given birth to so many Indian languages like, Tulu, Kodava etc and one of the scheduled languages of India and the official and administrative language of the state of Karnataka [5] . Telugu is also one of the widely spoken languages in India especially in the state of Andhra Pradesh and the district of Yanam. The number of consonants and vowels in Baraha Kannada/Telugu script as given in [Fig-2] . Both Kannada and Telugu use the “UTF-8” / western windows encode and draw their vocabulary mainly from Sanskrit.
[Table-1] .
Here multiple characters in one character set leads to single character in another character set. This problem makes transliteration process difficult. This type of problem is associated with characters shown in [Table-2] .
For example, in following name, combination of two characters ‘ch’ in English language forms the single character in Kannada language ‘Chaitra’.
This is similar to above explained problem. Here again two characters are clustered and mapped to single character in target language but clusters are made with ‘double occurrence’ of certain Characters in English language as shown in Table V. For example, ‘oo’ in word ‘cool’ are clustered to make one unit because they represent single character in target language. This type of clustering is associated with the following combination of characters.
Schwa deletion is an important issue in grapheme-to-phoneme conversion for Indo-Aryan languages. Schwa is defined as the mid-central vowel that occurs in unstressed syllables [9] . Simple observation of Hindi words [7] provides certain information where schwa is retained and certain contexts where it is deleted without any exception. For example, name ‘sapna’ is transliterated into whereby ‘a’ in between character ‘s’ and ‘p’ is deleted and ‘a’ after character ‘n’ is retained. To find out when to retain schwa sound is not a trivial task.
There can be multiple ways to write a source language word into target language. For example, for person name ‘Rabindranath Tagore’, two representations among various transliterations in target Kannada language are. Choosing the correct one is again depends upon the perception of end user.
In this section, we focus on the setup for the experiments and a performance evaluation of the proposed model applied to extract bilingual word pairs from parallel corpora.
Several corpora were collected to estimate the parameters of the proposed models and to evaluate the performance of the proposed approach. The corpus BUBShabdaSagara-2011 [14] for training consisted of 3,500 pairs of English names and transliterations in Kannada and Telugu. The training corpus composed of a bilingual proper name list. The bilingual proper name list consists of first names, last names, and nicknames. For example, (Kalpna, , ) and (vishwa , ) are first names, (khatriki, , ) and (Rao, , ) are last names, and (pinko, , ) and (chakul, , ) are nicknames, for males and females, respectively. Some first names are also used as last names. For instance, “Reddy” can be either a first name or a last name.
All the experiments carried out here involve the same set of English queries and the same query expansion, translation and retrieval method. The only difference between the experimental conditions is in what dictionaries are used in the query translation. Some samples from the training set BUBShabdaSagara-2011 as shown in [Table-3] .
In the experiment, we dealt with personal and place names as well as their transliterations from the parallel corpora. The performance of transliteration extraction was evaluated based on the precision rates of transliteration words or characters. For simplicity, we considered each proper name in the source sentence in turn and determined its corresponding transliteration independently.
We perform experiment in Linux environment. The following sections describe briefly the software that was used during the project.
Moses is a statistical machine translation system that allows to automatically train translation models for any language pair. Only translated texts (parallel corpus) is needed. An efficient search algorithm finds quickly the highest probability translation among the exponential number of choices [13] .
GIZA++ is an extension of the program GIZA which was developed by the Statistical Machine Translation team during the summer workshop in 1999 at the Center for Language and Speech Processing at Johns-Hopkins University [12] . GIZA++ is a program for aligning words and sequences of words in sentence aligned corpus. We used it to do character alignment of word-aligned pairs.
SRILM is a toolkit for building and applying statistical language models (LMs), primarily for use in speech recognition, statistical tagging and segmentation. SRILM is used by Moses to build statistical language models [10] .
In the experiment, the performance of transliteration extraction was evaluated based on precision and recall rates at the word and character levels. Since we considered exactly one proper name in the source language and one transliteration in the target language at a time, the word recall rates were same as the word precision rates:
The character level recall and precision rates were defined as follows:
Cross Language Information Retrieval Tool is built by using the ASP.NET as front end and for a Database the Kannada is encrypted by using the Encoding system. The sample result as shown in [Fig-3] .
The result statistical Transliteration system from English to Kannada/ Telugu for The corpus BUBShabdaSagara-2011 trained data set in [Table-4] .
We presented our English-Kannada and English-Telugu CLIR system developed for the Ad-Hoc bilingual Task. Our approach is based on query Translation using bi-lingual dictionaries. A new statistical modeling approach to the machine transliteration problem has been presented in this paper. The parameters of the model are automatically learned from a bilingual proper name list. Moreover, the model is applicable to the extraction of proper names and transliterations. The proposed method can be easily extended to other language pairs that have different sound systems without the assistance of pronunciation dictionaries. Experimental results indicate that high precision and recall rates can be achieved by the proposed method.
[1] Jong-Hoon Oh Key-Sun Choi (2005) IEICE TRANS. INF. & SYST., VOL. E88-D, NO. 7, pp 1737-1748.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[2] Jasleen kaur, Gurpreet Singh Josan (2011) International Journal on Computer Science and Engineering (IJCSE) ISSN: 0975-3397 Vol. 3 No., 1518.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[3] Hall P.A.V. and G.R. Dowling (1980) 12, 381-402.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[4] Karen Kukich (1992) ACM Comput. Surv. 24 (4): 377-439.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[5] Virga and S. Khudanpur (2003) Proceedings of the ACL Workshop on Multi-lingual Named Entity Recognition 2003.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[6] English Language Accessed from “http://en.wikipedia.org/wiki/English_language”, on Jan 2010.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[7] The Karnataka Official Language Act, Government of Karnataka. Retrieved 2007-06-29.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[8] Philipp Koehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico,Nicola Bertoldi, Brooke Cowan, Wade Shen, Christine Moran, Richard Zens, Chris Dyer,Ondrej Bojar, Alexandra Constantin, Evan Herbst (2007) Moses: Open Source Toolkit for Statistical Machine Translation, Annual Meeting of the Association for Computational Linguistics (ACL), demonstration session, Prague, Czech Republic.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[9] Article SRILM accessed from http://www.speech.sri.com/projects/srilm/on 2011.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[10] Mallamma V. Reddy, Hanumanthappa M. http://bangaloreuniversitydictionary//menu.asp.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[11] GIZA++ accessed from “http://www.fjoch.com/GIZA++.html” on 2011.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[12] Article GIZA++ accessed from http://wiki.apertium.org/wiki/Using_GIZA%2B%2B on 2011.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[13] Moses article accessed from http://www.statmt.org/moses/manual/manual.pdf on 2011.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[14] Mallamma V. Reddy, Hanumanthappa M. (2011) International Journal of Computer Science and Information Technologies, Vol. 2 (5), page-1876-1880. IISN: 0975-9646.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
 | Fig. 1- The overall process for extracting name and transliteration pairs |
 | Fig. 2- English-Kannada/Telugu Character Mapping |
 | Fig. 3- sample result for Kannada/Telugu |
 | Table 1- Multi-mapped Characters |
 | Table 2- Multi-to-One Map Problems |
 | Table 3- Some samples from the training set BUBShabdaSagara-2011 |
 | Table 4- The average rates of transliterated word extraction for overall corpora |