ISSN : 0975-2927
EISSN : 0975-9166

ABDULBARI AHMED ALI1*, RAMTEKE R.J.2*
1Department of Computer Science, North Maharashtra University,Jalgaon-425001 (M.S.), INDIA
2Department of Computer Science, North Maharashtra University,Jalgaon-425001 (M.S.), INDIA
* Corresponding Author : rakeshramteke@yahoo.co.in
Received : 29-09-2011 Accepted : 03-11-2011 Published : 07-11-2011
Volume : 3 Issue : 3 Pages : 116 - 120
Int J Mach Intell 3.3 (2011):116-120
DOI : http://dx.doi.org/10.9735/0975-2927.3.3.116-120
Conflict of Interest : None declared
Human generated patterns like handwritten characters are found to be fuzzy in nature upto certain extent. This presented work proposes a fuzzy conceptual approach to classify Handwritten Arabic Numerals based on invariant moments features and the divisions of numeral image into several parts. The Moment invariants features are well known for independence of size, slant, orientation, translation and other variations of handwritten characters. A database, created by American University in Cairo, of 7000 samples of each number from 700 different writers is used. Each image is normalized to 40X40 pixel size. Seven central invariant moments are evaluated for each image and its parts by dividing it by three different ways, i.e. three feature groups. The algorithm is experimented for 500 samples of each numeral image and 161 features were evaluated corresponding to each image. The performance rate of the method is found to be 95.14%.
Handwritten Arabic Characters, Feature Extraction, Invariant Moments, Segmentation, Classification, Fuzzy Membership Function.
The system based document processing is one of the major trends of office automation. The goal of Optical Character Recognition (OCR) is to classify optical patterns (often contained in a digital image) corresponding to alphanumeric or other characters.
An OCR has a variety of commercial and practical applications in reading forms, manuscripts and their archival etc. It can be used as a reading machine for the visually handicapped when interfaced with a voice synthesizer. Recognition of handwritten numerals is important because of its applicability in various fields like postal code recognition, phone no., check processing etc. The recognition can be achieved by many methods such as dynamic programming, hidden Markov modeling, neural network, nearest neighbor classifier, expert system and a combination of all these techniques.
Thus all the above advantages under consideration, Arabic character recognition prove to be an interesting area for research. Several recognition techniques have been used over the past few decades by many researchers. These techniques were applied for the automatic recognition of both printed and hand printed characters. Immense research has been expanded on the recognition of Latin, Chinese and English characters [1] . Against this background, only few papers have been addressed to the problem of Arabic character recognition. Recognition of Handwritten Arabic Numerals/ Characters is a complicated task due to the cursive and unconstrained shape variations, different writing style and different kinds of noise that break the strokes primitives in the character or change their topology. Unlike English and other Roman scripts, Arabic has a few, if any, commercial OCR renders; and the ones that have products provide only the custom enterprise solutions. Recognition of handwritten Arabic/Persian digits is attempted based on Support Vector Machines (SVMs), on symbolic representation and on coding and an edited probabilistic neural network [2,3,4] .
In the field of handwriting recognition, it is now established that a single feature extraction method and a single classification algorithm generally can’t yields a very low error rate. Therefore it is proposed that certain combination of features can create better success rates. Three major factors can however justify such an approach (i) the use of several types of features still ensures an accurate description of the characters; (ii) the use of a single classifier preserves fast and flexible learning; (iii) the tedious tuning of combination rule is avoided [5] .
Moment based features are a traditional and widely used tool for character recognition. Classical moment invariants were introduced by Hu (1962) which is invariant under translation, rotation and scaling. However, Hu’s moments are not derived from family of orthogonal functions, and so contain much redundant information about a character’s shape. Hence, Zernike moments based on the theory of orthogonal polynomials are becoming popular for character recognition nowadays [6] . Since handwritten characters are inclusive of variations in style fonts etc. Simply moments do not yield expected results. It is, therefore, character image is divided into several parts and features are extracted.
In this work a database, created by American University in Cairo, of 7000 samples of each number from 700 different writers is used containing numeral images in variety in handwriting style. The results reported in this paper are more reliable and satisfactory as compared to existing techniques in terms of features, classifiers and environment. The paper is organized as follows: Section 2 deals with introduction to Arabic numerals. Section 3 deals with Invariant Moments. The theory of different methods experimented is discussed in section 4. The section 5 deals with recognition phase. The section 6 provides discussion regarding results and conclusion and future work is in section 7.
Arabic is a Central Semitic language, thus related to and classified alongside other Semitic languages such as Hebrew and the Neo-Aramaic languages. In terms of speakers, Arabic is the largest member of the Semitic language family. It is spoken by more than 280 million people as a first language, most of whom live in the Middle East and North Africa, and by 250 million more as a second language [7] .
Arabic script is written from right to left, and letters within a word are normally joined even in machine-print. There is no connection between separate words, so word boundaries are always represented by a space. There is no upper or lower case, but only one case. Letters are connected at the same relative height. The "baseline" is the line at the height at which letters are connected, and it is analogous to the line on which an English word sits [8] .
An image moment is a certain particular weighted average (moment) of the image pixels' intensities, or a function of such moments, usually chosen to have some attractive property or interpretation. Image moments are useful to describe objects after segmentation. The Moment Invariants (MIs) are used to evaluate seven distributed parameters of a numeral image. The MIs are invariant under translation, rotation, scaling and reflection [ 8, 6, 9, and 5 ]. They are measures of the pixel distribution around the center of gravity of the character and allow capturing the global character shape information. In the present work, the moment invariants are evaluated using central moments of the image function f(x, y) up to third order. Regular moments are defined as [9] .
(1)
where for p, q = 0,1,2,…. and and
are moments evaluated from the geometrical moments mpq as follows,
and
(2)
(3)
The normalized central moment to shape and size of order (p+q) is defined as
(4)
for p,q = 0,1,2,…Where (5)
for (p+q) = 2,3,…
A set of seven moment invariants can be derived from equations (6)
While processing, each image is resized into 40X40 pixel image. The image obtained represents the number with black color on a white background. Image complement function is applied to obtain the character with white color on black. The evaluated 7 central invariant moments i.e. (Ï•1-Ï•7) are used as features. Further, mean and standard deviation are determined for each feature using 500 samples. Thus we had 14 features (7 means and 7 standard deviations), which are applied as features for recognition using Fuzzy Gaussian Membership Function. In order to increase the success rate, new features need to be extracted based on divisions of the images. The total features of this work are 24X7=168 features.
As mentioned above, the concept of invariant moment i.e. invariant to reflection, there is problem in recognition of (2, 6) and (7, 8) because of their similarity under reflection. The recognition rate was found to be only 66.84% by using the seven invariants of each numeral. To increase the success rate, the image is divided into 4 zones (Upper-left, Lower-Left, Upper-Right and Lower-right) as shown in [Fig-2] on the basis of centroid of the character image. After getting the center, the invariants moment features of each parts are evaluated. Thus in total there are 28 features in addition to the 7 original features. By using these 35 features, the recognition rate was found to be 90.66%.
Another way of extracting features and increasing the success rate from image is dividing image into two zones (2 vertical & 2 horizontal) as shown in [Fig-3] . This method gives more information with different features as compare to 4 zones. Thus additional 28 features are evaluated. By using these features (28 + 35) the recognition rate can be enhanced unto 91.78% from 90.66%.
[Table-1] shows the increasing in success rate and [Fig-4] represents the graphical representation of recognition in Feature Group 1.
Due to the close similarities between (2 and 3) and to get different shape of numeral images, the image is divided into two zones (2 vertical, 2 horizontal, 2 right diagonal and 2 left diagonal) as shown in [Fig-5] . In this way, one half (zone) is replaced into the other half (zone) and 7 moment invariants are calculated and vice versa. For example, in vertical case, the left zone is replaced into the right zone and vice versa and 7 moment invariants are calculated. in this way 56 features are evaluated. The available feature till now is 56+63; the recognition rate can be enhanced unto 93.74 % from 91.78%.
In order to improve the success rate of the recognition, selecting some portions of the image and zeroing the remaining portions is needed. This technique includes selecting the upper triangle and zeroing the remaining portion as shown in fig.6 (b). The same way has been done for lower, right, upper and lower, and left and right triangles as shown in fig.6 (c , d , e and f). In addition, the heart of the image is selected and the boarder of the image is zeroed as shown in fig.6 (g).
As shown in [Fig-6] , the left triangle has been omitted due to no benefit from its features. In this feature group, we have 42 features. When applying these 42 features in addition to 119 previous features, the recognition rate can be enhanced unto 95.14% from 93.74%.
A database, created by American University in Cairo, of numerals has been used to extract the features, which form a template (Trained Database). Then, the mean and standard deviation are computed for each type of features for numerals from 0 to 9. The unknown character features are matched with all reference character features
available in each group and found the maximum membership value (0-1) of the character with the reference character in the corresponding group. The template consists of mean Mi and standard deviation σi for each feature and computed as [11] :
Mean (10)
Standard Deviation (11)
Where Ni is the number of samples in ith class and Ï•i(k) stands for the kth feature value of reference character in the ith class.
The Fuzzy Gaussian Membership Function is used to get the maximum membership value as follows [10] :
(12)
Where xi is the ith feature of the unknown character.
Let Mj(r), belongs to the rth reference character which is any character class in the group. Then, the average membership value has been calculated as
(13)
where x □r if µav (r) is the maximum for r. Each feature class has its own array. The resultant array could be then normalized in order to enhance the success rate using the following equation.
(14)
Where N is, 10, the number of classes in the group, di is ith feature of class d.
Normalization (15)
The best recognition rate was found with three feature groups of image partition and invariant moments features. The promising performance of 95.14% at handwritten Arabic numerals has been achieved as shown in [Table-2] and [Fig-7] , which shows the graphical representation of the result. This technique overcomes the problems in varieties in handwriting style.
In feature we are going to apply this technique on other Arabic small markings called "diacritical marks" represent short vowels as shown in [Fig-8] .
[1] Koerich A.L., Sabourin R. and Suen C.Y. (2003) Patten Analysis Application, 6, 97-121.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[2] Javad S., Ching Y. S. and Tien D.B. (2003) 2nd MVIP, 1.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[3] Alireza A., Nagabhushan P. and Umapada P. (2009) Proceedings of the second International Conference on Signal and Image processing (ICSIP-2009), Mysore- India, published by Excel India Publishers, New Delhi-India, 435 – 439.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[4] Shirali-Shahreza H., Faez K. and Khotanzad A. (1995) International Conference on Image Processing (ICIP'95), 3, 34-36.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[5] Ramteke R. J., Bhagile V. D. and Mehrotra S. C. (2008) Proceedings of the international Conference in Advances in Computer Vision and Information Technology, published by I. K. International Publishing House, New Delhi, 1291-1301.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[6] Sanjeev, Kunte R. and Sudhakar R. D. (2007) Sadhana, 32 (5), 521-533.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[7] Lorigo L.M. and Venu G. IEEE transaction on pattern analysis and machine intelligence.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[8] Amin A. and Al-Sadoun H. (1992) 11th Int. Conf. on Pattern Recognition, 441-445.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[9] Gonzalez R. C. and Woods R. E. (2004) Pearson Education, 2E.
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
[10] Ramteke R.J. (2010) International Journal of Computer Applications (0975-8887), 1 (18).
» CrossRef » Google Scholar » PubMed » DOAJ » CAS » Scopus
 | Fig. 1- Handwritten Arabic Numerals |
 | Fig. 2- Numeral ‘3’ Divided into 4 zones |
 | Fig. 3- (a) Vertical division of ‘4’ (Left and Right). (b) Horizontal division of ‘4’ (Up and Down) |
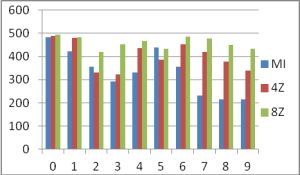 | Fig. 4- The increasing in recognition rate of Feature Group 1, Z- Zone |
 | Fig. 5- (a) Original numeral 5 image. (b) Upper part. (c) Lower part. (d) Left part. (e) Right part. (f) Upper left diagonal. (g) Lower left diagonal. (h) Lower right diagonal. (i) Upper right diagonal |
 | Fig. 6- (a) The original (3) image (b) Upper triangle (c) Lower triangle (d) Right triangle (e) Left and right triangle (f) Upper and lower triangle (g) heart of the image. |
 | Fig. 7- The graphical representation of the recognition rate of numerals MFG1-MI+FG1, MFG2-MI+FG1+FG2, MFG3-MI+FG1+FG2+FG3 |
 | Fig. 8- Diacritical marks: 1-fat-ha, 2-dumma, 3-kesra, 4-sukkon, and 5- nunation |
 | Table 1- Increasing rate in Feature Group 1 |
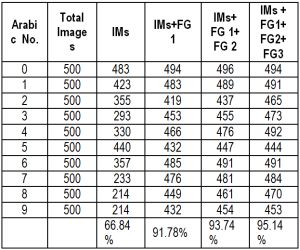 | Table 2- Recognition result of Arabic handwritten numerals. IMs- Invariant Moments, FG - Feature Group i |